ClawHosters
von Daniel Samer
16 Min. Lesezeit
Lädt...
60 Sekunden. Das war das Ziel. Button klicken, laufende OpenClaw-Instanz bekommen.
Was ich tatsächlich gebaut hab: Ein vierschichtiges Security-Modell. Einen Pool von vorgebooteten VPS-Instanzen im Leerlauf, die darauf warten beansprucht zu werden. Ein Container-Commit-System, damit Nutzeränderungen Neustarts überleben. Dynamisches Routing über Redis. Alles davon läuft in einer einzigen Rails-App. Von mir alleine. In etwa einer Woche.
Die Domain wurde am 5. Februar registriert. Dieser Post ging sechs Tage später online.
Hier ist, was ich im Rabbit Hole gelernt hab. Falls dich interessiert, warum ich ClawHosters überhaupt gebaut habe, das ist eine eigene Geschichte.
Kurzer Kontext für alle, die es noch nicht kennen. OpenClaw ist ein Open-Source-KI-Agent-Framework. Du installierst es auf einem Server, verbindest es mit einem LLM deiner Wahl (Claude, GPT-4, Gemini) und bekommst einen persönlichen KI-Assistenten. Der funktioniert über Telegram, Discord, Slack, WhatsApp. Er kann im Web surfen, Code ausführen, Pakete installieren, Aufgaben automatisieren.
Stell dir das wie einen selbstgehosteten KI-Assistenten vor, der tatsächlich Dinge erledigt, nicht nur chattet.
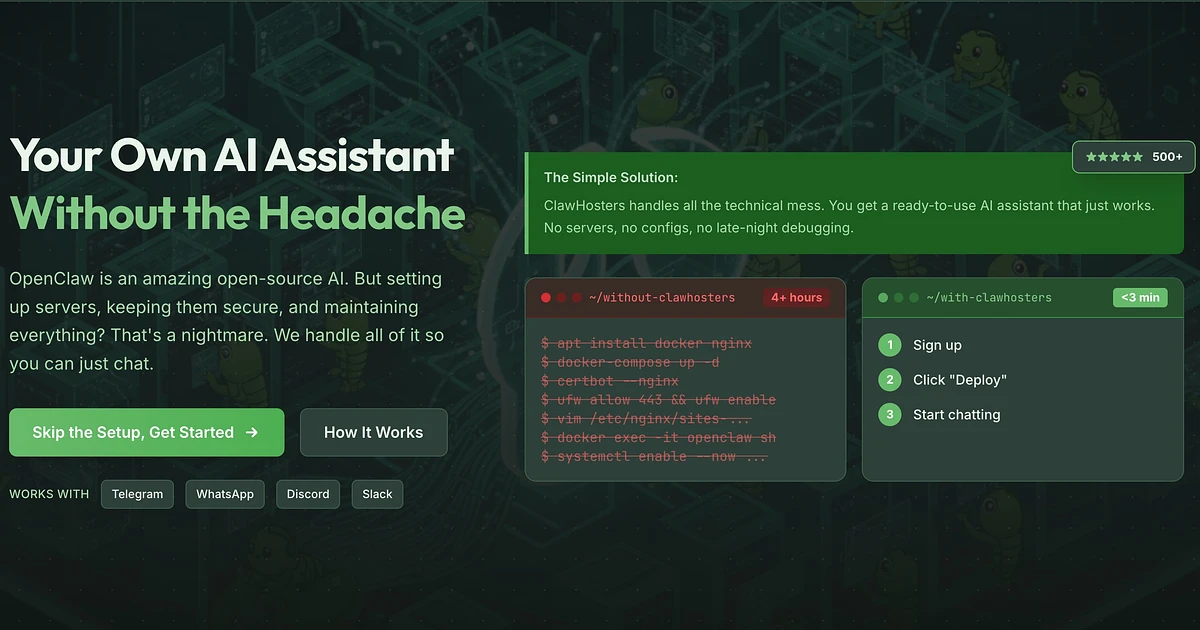
Das Problem: es selbst aufzusetzen nervt.
Ich hab Ende 2025 versucht, OpenClaw auf einem VPS einzurichten. Der Prozess sah ungefähr so aus:
Und dann fängt der eigentlich unangenehme Teil erst an.
Das sind etwa 45 Minuten, wenn du weißt was du tust. Die meisten wissen es nicht. Und ehrlich gesagt wollen die meisten es auch nicht wissen. Sie wollen ihren KI-Assistenten auf Telegram laufen haben, und zwar jetzt.
Also hab ich ClawHosters gebaut. Eine managed OpenClaw-Hosting-Plattform. Tier wählen, Button klicken, laufende Instanz mit Subdomain bekommen. Das Ziel war 60 Sekunden oder weniger, OpenClaw-Hosting so einfach wie sich für ein SaaS-Produkt anzumelden.
Ich hab das Ziel erreicht. Aber der Weg dahin war nicht geradlinig.
So sieht der vollständige Request-Pfad für unsere OpenClaw-Hosting-Infrastruktur aus, wenn jemand mybot.clawhosters.com aufruft:
User-Browser
|
v
DNS (Cloudflare)
|
v
Production Server (unsere statische IP)
|
v
Traefik (liest Routing aus Redis)
|
v
Kunden-VPS bei Hetzner (IP aus Redis)
|
v
VPS nginx (validiert Host Header)
|
v
Docker Container (Port 18789)
|
v
OpenClaw Gateway liefert Response
Jeder Request durchläuft diese Kette. Der Browser des Nutzers trifft auf Cloudflare, das auf meinen Production Server auflöst. Traefik auf diesem Server schlägt die Subdomain in Redis nach, findet die Ziel-VPS-IP und proxied den Request dorthin. Der VPS betreibt nginx, das den Host Header validiert (direkter IP-Zugriff wird abgelehnt), und leitet dann an den Docker Container auf Port 18789 weiter. Das OpenClaw Gateway im Container liefert die Response.
Jede Subdomain verlangt außerdem HTTP Basic Auth, konfiguriert pro Instanz über Traefik Middleware Keys in Redis. Und der VPS selbst akzeptiert nur Verbindungen von der IP meines Production Servers (erzwungen auf Hetzner Cloud Firewall-Ebene). Es gibt also keine Möglichkeit, die Proxy-Kette zu umgehen.
Die gesamte Plattform läuft innerhalb einer einzigen Rails-App (derselben, die auch meine Portfolio-Seite ausliefert). ClawHosters hat eine eigene Domain, aber nginx schreibt clawhosters.com/* auf die /openclaw/*-Routen der Rails-App um.
Mein erster Versuch nutzte cloud-init, um alles von Grund auf auf einem frischen Ubuntu-VPS aufzusetzen:
#cloud-config
packages:
- docker.io
- docker-compose
- fail2ban
runcmd:
- systemctl enable docker
- docker pull ghcr.io/phioranex/openclaw-docker:latest
# ... Playwright-Browser installieren
# ... iptables konfigurieren
# ... Container starten
Das funktionierte. Dauerte aber etwa 5 Minuten. Manchmal länger, wenn der Docker-Image-Pull langsam war.
Fünf Minuten sind okay für einen Entwickler, der einen Server aufsetzt. Für ein Produkt, das schnelles Deployment verspricht, ist das miserabel.
Die Lösung war im Nachhinein offensichtlich. Alles in einen Hetzner Snapshot vorbacken. Dieser Ansatz ist die Grundlage für schnelles OpenClaw-Hosting. Durch Eliminierung der Installationsschritte verwandeln wir 5-Minuten-Provisioning in 60 Sekunden.
Der Snapshot enthält alles, was ein VPS zum Laufen braucht:
Ubuntu 24.04 mit Sicherheitsupdates
Docker und docker-compose, bereits installiert
Das OpenClaw Docker Image, bereits gepullt
Playwright Chromium Browser in einem benannten Docker Volume
Dazu der ganze Security-Kram:
iptables Firewall-Regeln
fail2ban, konfiguriert und laufend
Unser eigenes SSH-fähiges OpenClaw-Image (clawhosters/openclaw-ssh)
Wenn wir einen VPS von diesem Snapshot erstellen, macht cloud-init nur noch das hier:
runcmd:
- dpkg-reconfigure openssh-server # Host Keys neu generieren
- systemd-machine-id-setup # Eindeutige Machine ID
- systemctl restart docker
- systemctl restart fail2ban
Das war's. Keine Paketinstallation, kein Docker Pull, keine Browser-Installation, kein Warten. Der VPS bootet in 30 bis 60 Sekunden, vollständig bereit für Deployment.
Das Deployment selbst dauert weitere 20 bis 30 Sekunden. Per SSH verbinden, docker-compose.yml und Config-Dateien per SCP hochladen, docker-compose up -d ausführen, warten bis der Health Check durchläuft. Vom Klick auf "Erstellen" bis "Deine Instanz läuft" vergehen etwa 90 Sekunden.
Aber 90 Sekunden fühlten sich immer noch langsam an für etwas, das als "One-Click Deployment" beworben wird.
Hier wird unser OpenClaw-Hosting-Ansatz ein bisschen ungewöhnlich.
Selbst mit Snapshots braucht Hetzner 30 bis 60 Sekunden, um einen VPS zu erstellen. Das ist Zeit, in der der Nutzer auf einen Ladebildschirm starrt. Also halte ich einen Pool von vorab provisionierten VPS-Instanzen bereit. Die stehen im Leerlauf, bereits gebootet und SSH-bereit.
Wenn ein Kunde eine Instanz erstellt:
ClaimPrewarmedVpsService prüft, ob ein verfügbarer VPS im Pool istFullDeployService lädt Config-Dateien hoch und startet die Containervps = OcPrewarmedVps.claim_for_tier!(@tier)
return not_claimed_result unless vps
unless verify_ssh(vps)
vps.update!(status: :failed)
return not_claimed_result("SSH verification failed")
end
update_hetzner_metadata(vps)
Der Pool füllt sich asynchron über PrewarmReplenishJob nach. Ein Background Job prüft die Pool-Stände und provisioniert bei Bedarf Ersatz-VPS-Instanzen aus dem Snapshot.
Mit Prewarming geht die User Experience von 90 Sekunden auf etwa 15 bis 20 Sekunden runter. Der Großteil davon ist Config-Dateien hochladen und auf den Docker Health Check warten.
Das ist der Teil, über den ich wahrscheinlich zu lange nachgedacht hab. Aber ich bereue es nicht.
Hier ist, womit ich's zu tun hab: Untrusted Docker Container, die als Root laufen. Nutzer können Pakete installieren, beliebigen Code ausführen, im Web surfen. Was immer sie wollen. OpenClaw BRAUCHT Root-Zugriff, weil Agents zur Laufzeit Browser und Python-Pakete installieren. Non-Root-Container würden die Hälfte der Use Cases kaputt machen.
Also wie macht man das nicht beängstigend? Mehrere Schichten. Viele davon.
Netzwerk-Level Firewall über Hetzners API. Das ist die Schicht, der ich am meisten vertraue. Wird bei jeder VPS-Erstellung angehängt, bevor sonst was läuft.
firewalls: Array(OpenClaw::Config.firewall_id)
Die Regeln erlauben eingehenden Traffic ausschließlich von unserer Production-Server-IP.
| Port | Protokoll | Quelle | Zweck |
|---|---|---|---|
| 22 | TCP | 203.0.113.1/32 | Host SSH |
| 2222 | TCP | 203.0.113.1/32 | Container SSH |
| 8080 | TCP | 203.0.113.1/32 | HTTP (Traefik proxied hier) |
| 9090 | TCP | 203.0.113.1/32 | Prometheus Metrics |
| ICMP | Any | 0.0.0.0/0 | Ping/Health |
Alles andere wird verworfen, bevor es den VPS überhaupt erreicht. Selbst wenn jemand die VPS-IP-Adresse herausfindet, kann er sich nirgends verbinden. Aller Traffic muss durch unseren Production Server und Traefik fließen.
In den Snapshot eingebacken. Default Policy ist DROP für INPUT und FORWARD, ACCEPT für OUTPUT (mit Ausnahmen).
Die interessanten Regeln sind die ausgehenden.
# Ausgehende SMTP blockieren (verhindert Spam-Relay)
iptables -A OUTPUT -p tcp --dport 25 -j DROP
iptables -A OUTPUT -p tcp --dport 465 -j DROP
iptables -A OUTPUT -p tcp --dport 587 -j DROP
# Ausgehende IRC blockieren (verhindert Botnet C2)
iptables -A OUTPUT -p tcp --dport 6667 -j DROP
iptables -A OUTPUT -p tcp --dport 6697 -j DROP
# SYN-Flood-Schutz
iptables -A INPUT -p tcp --syn -m limit --limit 30/s --limit-burst 60 -j ACCEPT
Warum beide Schichten? Falls es jemand schafft, iptables innerhalb des Containers zu flushen (sollte nicht möglich sein, aber nehmen wir's mal an), blockt die Hetzner Cloud Firewall trotzdem alles auf Netzwerkebene. Und falls Hetzners Firewall einen Bug oder eine Fehlkonfiguration hat, fängt iptables es ab.
SSH-Brute-Force-Schutz. Drei fehlgeschlagene Versuche und du bist eine Stunde gesperrt. In den Snapshot eingebacken, läuft auf jedem VPS. Wobei Brute-Forcing ohnehin unmöglich ist, weil Passwort-Authentifizierung komplett deaktiviert ist. Sowohl der Host SSH (Port 22) als auch der Container SSH (Port 2222) akzeptieren ausschließlich Public-Key-Authentifizierung. fail2ban ist im Grunde Gürtel-und-Hosenträger für den Randfall, dass jemand sshd_config falsch konfiguriert.
Schicht 4 ist langweilig aber notwendig. Docker Daemon Config:
{
"no-new-privileges": true,
"log-driver": "json-file",
"log-opts": { "max-size": "50m", "max-file": "3" },
"default-ulimits": {
"nofile": { "Hard": 65536, "Soft": 32768 }
}
}
Log-Rotation verhindert Plattenfülle. no-new-privileges verhindert Privilege Escalation innerhalb von Containern. Und Ulimits verhindern File-Descriptor-Erschöpfung.
Sind vier Schichten übertrieben? Vermutlich. Aber ich hab gesehen, was passiert wenn man einer einzelnen Security-Grenze vertraut und sie versagt.
Über diese Designentscheidung hab ich lange hin und her überlegt. Sollte Docker-Hosting für OpenClaw direkten Container-SSH-Zugang beinhalten oder ihn sperren?
Nutzer wollen manchmal eigene Pakete installieren, Probleme debuggen oder ihre OpenClaw-Instanz über das Web-UI hinaus anpassen. Die Frage war, ob ich ihnen SSH-Zugang zum eigentlichen Docker Container gebe.
Ich hab mich für ja entschieden. Aber mit Bedingungen.
Wir bauen ein eigenes Docker Image (clawhosters/openclaw-ssh), das das Community OpenClaw Image um einen OpenSSH Server erweitert. Port 2222 auf dem Host mappt auf Port 22 im Container. Der SSH Server startet automatisch, aber mit einer leeren authorized_keys-Datei. Obwohl der Port gemappt ist, kann sich also niemand verbinden, bis der Nutzer SSH explizit aktiviert und seinen Public Key hinterlegt.
class EnableSshAccessService
SSH_HOST_PORT = 2222
def call
validate!
@instance.enable_ssh!(public_key: @public_key)
configure_ssh_in_container
# ...
end
end
Der Service verbindet sich per SSH auf den VPS (mit unserem Master Key auf Port 22) und nutzt dann docker exec, um den Public Key des Nutzers in /root/.ssh/authorized_keys innerhalb des laufenden Containers zu schreiben. Kein Container-Neustart nötig.
Der Tradeoff dabei ist, dass SSH zu aktivieren die Instanz dauerhaft als no_support markiert. Wir können keine Stabilität garantieren, wenn jemand willkürlich Pakete installiert und Systemdateien verändert hat. Der Nutzer sieht eine klare Warnung, bevor er bestätigt.
Der Container läuft als Root. Das ist Absicht. OpenClaw-Agents müssen zur Laufzeit Browser, Python-Pakete, Node-Module und System-Libraries installieren. Als Non-Root-User zu laufen würde die Hälfte der Anwendungsfälle kaputt machen.
Das ist wahrscheinlich der Teil, auf den ich am stolzesten bin, obwohl er peinlich einfach ist. Es ist das, was einfaches VPS-Provisioning von einer wirklich gemanagten OpenClaw-Hosting-Erfahrung unterscheidet.
Docker Container haben eine beschreibbare Schicht, die zerstört wird wenn der Container entfernt wird. Wenn ein Nutzer apt-get install ffmpeg in seinem OpenClaw Container ausführt und wir später erneut deployen (für eine Config-Änderung oder ein OpenClaw-Update), ist ffmpeg weg.
Die Lösung heißt CommitContainerService.
Vor jedem Neustart oder Redeploy führen wir docker commit auf dem laufenden Container aus, um seinen gesamten Dateisystem-Zustand als neues Image zu speichern:
def perform_commit(ssh)
container_name = Shellwords.escape("openclaw-#{@instance.id}")
committed_image = "clawhosters/openclaw-#{@instance.id}-user:latest"
# Nur laufende Container committen
status = ssh.exec!("docker inspect -f '{{.State.Running}}' #{container_name}")
return skip_result unless status.strip == "true"
output = ssh.exec!("docker commit #{container_name} #{committed_image}")
# ...
# Image-Name speichern, damit DockerComposeTemplate ihn beim nächsten Mal nutzt
@instance.update!(
metadata: @instance.metadata.merge("committed_image" => committed_image)
)
end
Beim nächsten Mal, wenn wir docker-compose.yml generieren, prüft DockerComposeTemplate ob ein committed Image existiert:
def committed_image_or_default
committed = @instance.metadata&.dig("committed_image")
committed.present? ? committed : "clawhosters/openclaw-ssh:latest"
end
Falls eines existiert, wird es anstelle des Base Image verwendet. Die vom Nutzer installierten Pakete überleben den Neustart.
Man kann sich das wie Git für den Dateisystem-Zustand des Containers vorstellen, nur dass es nur einen "Commit" gibt und der jedes Mal überschrieben wird. Nicht elegant, aber es funktioniert und Nutzer verlieren ihre Anpassungen nicht.
Ein Sonderfall, den ich behandeln musste. Wenn ein VPS zerstört und neu erstellt wird (passiert bei Tier-Wechseln oder Migrationen), existiert das committed Image auf dem neuen VPS nicht. FullDeployService löscht dann die committed_image-Metadaten, sodass auf das Base Image zurückgefallen wird.
def clear_committed_image_metadata
return unless @instance.metadata&.key?("committed_image")
@instance.update!(metadata: @instance.metadata.except("committed_image"))
end
Jede OpenClaw-Hosting-Instanz bekommt eine Subdomain wie mybot.clawhosters.com. Ich brauchte eine Möglichkeit, jede Subdomain zum richtigen VPS zu routen, ohne Konfigurationsdateien neu zu laden.
Nginx würde funktionieren, aber eine neue Subdomain hinzuzufügen bedeutet eine Config-Datei zu schreiben und nginx -s reload auszuführen. Für ein paar Instanzen reicht das. Aber ich wollte etwas, das sich in Echtzeit aktualisiert, ohne Reload oder Restart.
Traefik mit einem Redis-Provider macht genau das. Traefik beobachtet Redis auf Key-Änderungen und aktualisiert seine Routing-Tabelle automatisch.
Wenn eine Instanz live geht, schreibt TraefikRoutingService ein paar Redis Keys:
redis.multi do |r|
# Basic Auth Middleware
r.set(middleware_key(middleware_name, "basicauth/users/0"), credential)
# Router: welche Subdomain auf welchen Service mappt
r.set(router_key(subdomain, "rule"), "Host(`#{subdomain}.clawhosters.com`)")
r.set(router_key(subdomain, "service"), subdomain)
r.set(router_key(subdomain, "entryPoints/0"), "web")
r.set(router_key(subdomain, "middlewares/0"), middleware_name)
# Service: wohin der Traffic proxied wird
r.set(service_key(subdomain, "loadbalancer/servers/0/url"),
"http://#{ip_address}:8080")
end
Das war's. Innerhalb von ein bis zwei Sekunden pickt Traefik die neuen Keys auf und beginnt Traffic zu routen. Kein Restart, kein Config-Reload, kein manueller Eingriff, kein Downtime für andere Instanzen.
Eine Route zu entfernen, wenn eine Instanz gelöscht oder pausiert wird, ist nur ein redis.del auf den relevanten Keys.
Ich konfiguriere auch HTTP Basic Auth pro Instanz über Redis Middleware Keys. Jede Instanz bekommt ihre eigenen bcrypt-gehashten Credentials (Kunden-E-Mail + automatisch generiertes Passwort). Der Nutzer sieht die Login-Daten in seinem Dashboard und kann das Passwort ändern.
Eine Sache, die ich erwogen aber nicht umgesetzt hab, ist TLS-Terminierung auf VPS-Ebene. Im Moment kümmert sich Cloudflare um TLS für *.clawhosters.com, Traefik empfängt reines HTTP und proxied zum VPS über reines HTTP auf Port 8080. Der VPS-nginx validiert dann den Host Header, um direkten IP-Zugriff zu verhindern. Es ist nicht Ende-zu-Ende verschlüsselt zwischen Traefik und dem VPS. Da aber aller Traffic über unsere private Infrastruktur fließt (Production Server zu Hetzner VPS), bin ich damit vorerst zufrieden. Vermutlich etwas, das ich nochmal überdenke.
Ich betreibe diese OpenClaw-Hosting-Plattform jetzt seit ein paar Monaten in Production. Hier ist was ich gelernt hab.
Das Credit-System mit Claws war im Nachhinein zu viel Komplexität zu früh. Statt direkt in EUR abzurechnen, kaufen Kunden "Claws" (unsere interne Credit-Einheit) und Instanzen verbrauchen täglich Claws. Der Umrechnungskurs, anteilige Tageskosten, Guthabenprüfung beim Provisioning, zeitzonenabhängige Abrechnungszyklen. Ich hätte wahrscheinlich mit einfachen Stripe-Subscriptions anfangen und das Credit-System später hinzufügen sollen. Oder nie. Ich hab vorher schon über Side Projects zu Produkten machen geschrieben. Das Muster ist immer gleich: für dich selbst lösen, Freunden helfen, Nachfrage bemerken, schnell shippen.
Das Snapshot-Management ist immer noch manuell. Ich hab Rake Tasks zum Erstellen und Aktualisieren von Snapshots, aber der Prozess ist nicht automatisiert. Wenn die Community ein neues OpenClaw-Image veröffentlicht, muss ich manuell einen neuen Snapshot mit dem aktualisierten Image bauen. Ich sollte eine CI-Pipeline haben, die den Snapshot wöchentlich neu baut. Steht auf meiner Liste.
Und dann sind da die Health Checks. Die sind zu gutgläubig. Mein Health Check akzeptiert jede HTTP-Antwort (200, 301, 302, 401, 403) als "Server lebt". Das sagt mir, dass der Container läuft und nginx proxied, aber nicht ob OpenClaw selbst korrekt funktioniert. Ein gründlicherer Check würde den Gateway-Endpoint gezielt prüfen. Ich hatte noch keine Probleme damit, aber ich weiß, dass das eine Lücke ist.
Weil Leute auf HN Konkretes mögen, hier sind die echten Zahlen hinter unserer OpenClaw-Hosting-Infrastruktur:
Provisioning aus Snapshot (ohne Prewarm): ca. 60 bis 90 Sekunden
Provisioning mit Prewarmed VPS: ca. 15 bis 20 Sekunden
Deployment (Config-Upload + Container-Start + Health Check): ca. 20 bis 30 Sekunden
Das Pricing und die Ressourcen sehen so aus:
Tiers: EUR 19/Monat (2 vCPU, 4 GB), EUR 35/Monat (4 vCPU, 8 GB), EUR 59/Monat (8 vCPU, 16 GB)
Docker Memory Limits: 1 GB, 2 GB, 4 GB je nach Tier
Zeilen Ruby im Provisioning-Layer: vermutlich um die 2.000
Zeit, die ich am Security-Modell gesessen hab: ehrlich gesagt zu lange. Aber ich schlafe gut.
Für die Neugierigen (ich scrolle immer zu diesem Abschnitt in anderen Posts, also hier der komplette OpenClaw-Hosting-Tech-Stack):
Backend: Ruby on Rails 8.0, PostgreSQL, Sidekiq
Infrastruktur: Hetzner Cloud (API für VPS-Management), Cloudflare (DNS + TLS)
Routing: Traefik mit Redis-Provider
Auf Container- und Ops-Seite:
Container: Docker mit eigenem SSH-fähigem Image
Monitoring: Prometheus + Grafana (jeder VPS exportiert Metrics auf Port 9090)
SSH: Net::SSH Gem für Ruby, ed25519 Master Key geteilt über alle Instanzen
Alles läuft auf einem einzelnen Production Server (Hetzner Dedicated), bis auf die Kunden-VPS-Instanzen, die Hetzner Cloud Instanzen sind. Das ist nicht mein erstes Mal Rails-Infrastruktur zu skalieren. Ich hab RLTracker auf 2,4 Millionen Trades skaliert und Splex.gg Rental-Automatisierung auf 60% Marktanteil gebracht.
Falls du unsere managed OpenClaw-Hosting-Plattform testen willst: ClawHosters.com. Der Budget-Tier kostet EUR 19 im Monat. Du kannst Telegram, Discord, Slack oder WhatsApp verbinden, deinen eigenen API-Key für Claude/GPT-4/Gemini mitbringen und in unter einer Minute einen laufenden KI-Assistenten haben.
Fragen zu irgendeinem Teil davon beantworte ich gerne. Der Quellcode ist (noch) nicht offen, aber ich überlege, den Provisioning- und Routing-Layer als eigenständige Libraries zu veröffentlichen. Falls das für dich nützlich wäre, sag Bescheid.
OpenClaw ist ein Open-Source-KI-Agent-Framework, mit dem du deinen eigenen persönlichen KI-Assistenten betreiben kannst. Es funktioniert über Telegram, Discord, Slack und WhatsApp, kann im Web surfen, Code ausführen, Pakete installieren und Aufgaben automatisieren. Denk daran wie an einen selbstgehosteten KI-Assistenten, der tatsächlich Dinge erledigt, nicht nur chattet.
Wir bieten drei Tiers an: Budget (EUR 19/Monat für 2 vCPU, 4GB RAM), Balanced (EUR 35/Monat für 4 vCPU, 8GB RAM) und Pro (EUR 59/Monat für 8 vCPU, 16GB RAM). Jeder Tier beinhaltet den VPS, Docker-Hosting, Subdomain, SSL und automatische Updates.
Aktuell nicht, aber der Budget-Tier kostet EUR 19/Monat. Weniger als die meisten Cloud-Plattformen für einen vergleichbaren VPS verlangen. Du kannst jederzeit kündigen, und das Setup dauert unter 60 Sekunden.
Sehr sicher. Wir nutzen vier Security-Schichten: Hetzner Cloud Firewall (Netzwerk-Level-Filterung), Host-iptables-Regeln (in Snapshots eingebacken), fail2ban mit Key-Only SSH, und gehärtete Docker-Daemon-Konfiguration. Alle Container laufen isoliert mit striktem Ausgangs-Port-Blocking (kein SMTP/IRC).
Ja. Du kannst SSH-Zugang zu deinem Docker-Container über das Dashboard aktivieren. Port 2222 gibt dir Root-Zugang innerhalb des Containers, sodass du eigene Pakete installieren oder Probleme debuggen kannst. Beachte, dass SSH zu aktivieren deine Instanz als `no_support` markiert.
Dein VPS und alle Daten werden gelöscht, wenn dein Abo endet. Falls du SSH aktiviert und Anpassungen gemacht hast, werden diese zwischen Neustarts via `docker commit` erhalten, überleben aber die Account-Kündigung nicht. Exportiere immer wichtige Daten vor der Kündigung.
Ja. ClawHosters ist standardmäßig bring-your-own-key (BYOK). Du verbindest deine eigenen LLM-API-Keys über das OpenClaw Web-UI, nachdem deine Instanz provisioniert wurde.

Vor zwei Wochen ging ClawHosters live. Heute läuft das Managed Hosting für KI-Agenten mit rund 50 zahlenden Kunden und 25 weiteren im Trial. Alles von Reddit, ohne Marketing-Budget, neben einem regulären 40-Stunden-Job.

Es war Samstagabend, kurz vor elf. Ich saß auf der Couch, Bier in der Hand, irgendeine Serie lief. Mein Handy vibrierte. Discord. "Hey Daniel, mein Bot antwortet nicht mehr. Kannst du mal gucken?"
